Roboty indeksujące – pośrednicy w procesie indeksowania i niewidoczni goście naszych portali WWW. Wpełzają, czytają, zbierają dane i raportują. Nieokiełznane, przeskanują całą zawartość serwisu internetowego; umiejętnie kontrolowane, skupią się na treści, na której nam najbardziej zależy. Dowiedz się, w jaki sposób możemy kontrolować naszych cichych gości.
Kontrolę robotów indeksujących możemy sprawować na różne sposoby. Z grubsza możemy sprowadzić ją do wykorzystania odpowiedniego tagu meta lub osobnego plik tekstowego o nazwie robots.txt (pisany małymi literami), w którym umieszczamy odpowiednie dyrektywy.
Meta robots
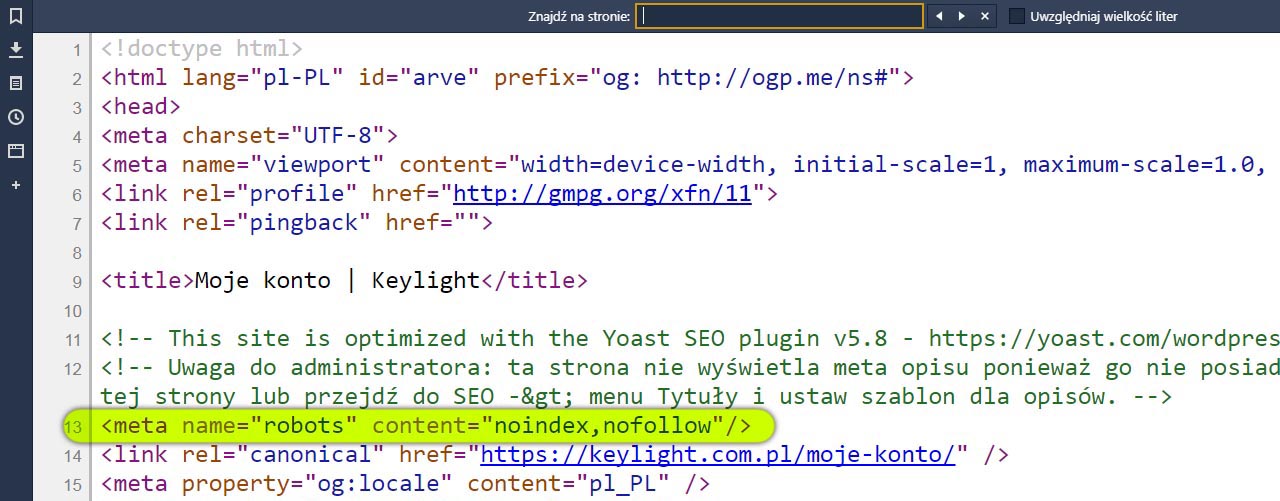
Metoda oparta na ręcznej edycji tagu meta robots, jest trochę archaiczna, ale pozwala zrozumieć ideę sterowania robotami indeksującymi. Wykorzystujemy w tym przypadku odpowiedni znacznik HTML umieszczany w sekcji head, czyli na początku strony WWW:
<meta name="robots" content="argument sterujący robotem" />
Argument „content” przechowuje odpowiednią wartość, która jest instrukcją dla robota (zobacz poniżej listę argumentów). Problem z tym rozwiązaniem polega na tym, że tego typu znacznik należałoby umieszczać na każdej stronie i podstronie WWW. W przypadku kilkunastu stron jest to jeszcze znośne. Co jednak w sytuacji, w której musimy pozycjonować serwis zbudowany z setki wpisów (blog) lub produktów (sklep internetowy)? Cóż, z pomocą przychodzi plik robots.txt.
robots.txt – jeden by rządzić wszystkimi
Umieszczanie instrukcji sterujących pracą robota indeksującego w sekcji head nie jest pasjonującym zajęciem. O wiele wydajniejsze rozwiązanie opiera się na pliku tekstowym, w którym wprowadzamy dyrektywy sterujące poszczególnymi robotami. Taki plik należy umieścić w głównym katalogu aplikacji webowej. Wiele wtyczek i dodatków dla rożnego typu CMSów, ułatwia ten proces, tzn. uzupełnia plik robots.txt i dynamicznie umieszcza go we właściwej lokalizacji (właściwie bez naszego udziału). Jeśli robot indeksujący nie znajdzie takiego pliku, to będzie starał się zindeksować cały serwis.

Dyrektywy sterujące pracą robota indeksującego
Wykorzystując wtyczki typu SEO możemy oznaczać treść pod kątem indeksowania na etapie tworzenia i edycji artykułów. W ten sposób nie musimy sięgać do sekcji head strony WWW – wszystko odbywa się na poziomie interfejsu. Tego typu narzędzia umożliwiają wygenerowanie pliku robots.txt i wstawienie go we właściwym miejscu. Dyrektywy znajdujące się w takim pliku są na tyle ogólne, że robot może swobodnie indeksować cały portal WWW.
Jeśli wtyczka SEO umożliwia edycję pliku robots.txt z poziomu panelu admina, to po prostu dopisujemy kolejne instrukcje. W innym wypadku należy pobrać plik na komputer, dodać linie kodu, zapisać i wysłać z powrotem na serwer. Przyjrzyjmy się standardowemu wpisowi dla aplikacji WordPress.
User-agent: * Disallow: /wp-admin/
User-agent to określenie na roboty indeksujące, po dwukropku możemy wpisać konkretną nazwę robota związanego w daną wyszukiwarką internetową (przykł. Googlebot). Jeśli wstawimy gwiazdkę to oznacza, że dyrektywa poniżej odnosi się do wszystkich robotów. Polecenie Disallow informuje robota, że nie powinien indeksować tego, co znajdzie po dwukropku, w tym przypadku katalogu wp-admin.
Jeśli zamiast nazwy katalogu pozostawilibyśmy znak slash [/], to dyrektywa blokująca indeksowanie odnosiłaby się do całego portalu WWW. Zamiast katalogu możemy także podać nazwę pliku, który nie powinien być indeksowany, przykładowo jakieś wewnętrzne dokumenty zapisane w rozszerzeniu PDF. Dodając linijki z poleceniem Disallow wskazujemy kolejne zasoby, które mają być wyłączone z indeksowania. Polecenie będące przeciwieństwem dla Disallow to Allow – zobaczmy na przykładzie:
User-agent: * Disallow: /chroniony-przykladowy-plik.pdf User-agent: GoogleBot Allow: / Sitemap: http://nazwa-domeny/sitemap.xml.gz
Powyższy zapis nie jest zbyt rozsądny, ale pozwoli wyjaśnić kilka rzeczy. Pierwsze dwie linijki odwołują się do wszystkich robotów (znak gwiazdki), a instrukcja disallow chroni wybrany plik PDF przed indeksowaniem. Kolejne dwie linijki odnoszą się do robota Google (zamiast gwiazdki nazwa bota), a instrukcja (znak /) zezwala na pełne indeksowanie portalu WWW.
Ostatnia linijka określa lokalizację pliku z mapą witryny. Jednak w tym przypadku mapa witryny generowana jest dynamicznie przez odpowiednią wtyczkę. Nic nie stoi na przeszkodzie, aby wygenerować własną mapę, umieścić na serwerze i w pliku robots.txt wskazać ścieżkę dostępu do mapy.
Umieszczenie dyrektyw w pliku robots.txt, nie oznacza, że wszystkie roboty indeksujące będą je przestrzegały. Należy liczyć się z tym, że mimo wszystko nasz portal WWW będzie skanowany w całej okazałości. Robotów jest bardzo dużo i zachowują się odmiennie. Plik robots.txt powinien być traktowany jako ogólne wskazówki dla robotów. Lista botów jest długa – pod wskazanym adresem znajdziemy wiele przykładów robotów indeksujących, ale należy pamiętać także o złych botach, które ignorują jakiekolwiek dyrektywy i skanują całe portale WWW.
Generowanie pliku robots.txt
Istnieje kilka sposobów na utworzenie pliku robots.txt (pamiętajmy, że nazwa pliku powinna składać się z małych liter):
- Plik możemy utworzyć ręcznie w notatniku. Określamy agenta (czyli nazwa robota indeksującego), wprowadzamy dyrektywy, zapisujemy plik i za pomocą bezpiecznego połączenia SFTP umieszczamy go głównym katalogu aplikacji webowej.
- Możemy także wykorzystać narzędzia wybranej wyszukiwarki internetowej. Wcześniej należy założyć konto i połączyć je z naszą witryna internetową. Po analizie struktury naszej strony możemy wykorzystać narzędzia do generowania pliku robots.txt. Plik zapisujemy i po wszystkim wysyłamy go na serwer.
- Najprostszy i najwygodniejszy sposób to wykorzystanie specjalnych wtyczek zajmujących się wspieraniem procesu pozycjonowania. Takie narzędzia z reguły automatycznie generują odpowiedni plik, następnie wprowadzają do niego uniwersalne dyrektywy i serwują go robotom indeksującym. Po stronie panelu admina mamy z reguły możliwość edycji pliku robots.txt.
Indeksowanie w praktyce na przykładzie WordPressa
Administrując portal WWW na bazie CMS’a, rzadko odwołujemy się do sekcji head każdej strony i wprowadzamy tam odpowiednie dyrektywy dla robotów indeksujących. Przeważnie wykorzystuje się wtyczki poświęcone SEO, które usprawniają proces pozycjonowania. Tego typu narzędzia mogą generować plik robots.txt z ogólnymi instrukcjami dla wszystkich robotów. Sam proces jest automatyczny i nie wymaga od nas większego zaangażowania.
Po wygenerowaniu pliku robots.txt możemy go edytować i wprowadzać szczegółowe dyrektywy. Możemy zablokować robotom dostęp do takich dokumentów jak regulamin, czy polityka prywatności – nie istnieje powód, aby tego typu treści pojawiały się w wynikach wyszukiwania. Przyznać jednak trzeba, że ręczne dopisywanie kolejnych linijek kodu nie jest zbyt zajmujące i efektywne.
Na szczęście, niektóre wtyczki pozwalają sterować procesem indeksowania w odniesieniu do poszczególnych wpisów oraz stron WWW. Jest to możliwe dzięki dodaniu niezbędnych opcji do edytora. Po prostu: tworząc treść określamy czy ma być indeksowana. Do tego celu wykorzystuje się odpowiednie opcje (a właściwie argumenty) typu: index lub noindex. Jest to o wiele wygodniejsze rozwiązanie, niż edytowanie pliku robots.txt.
Lista argumentów sterujących pracą robotów
Argumenty poniżej pozwalają sterować pracą robotów indeksujących. Są one wykorzystywane w sekcji head naszej strony WWW i zamknięte w znaczniku meta:
<meta name="robots" content="noindex" />
Na szczęście wykorzystując wtyczki pozycjonujące możemy wybierać odpowiednie opcje podczas edycji treści. Podstawowe argumenty to: index, noindex, follow, nofollow. Poniżej znajduje się krótka lista argumentów:
- index – indeksuj stronę WWW. Jest to domyślna wartość dla każdej strony – niezależnie od jej obecności, strona zostanie zindeksowana.
- noindex – nie indeksuj strony WWW. Odnosi się to do wyświetlania strony w wynikach wyszukiwania; robot tak czy owak odwiedzi i przeskanuje stronę.
- follow – robot podąża za odnośnikami na stronie WWW niezależnie od tego, czy blokujemy ją przed indeksowaniem.
- nofollow – robot nie będzie podążał za odnośnikami znajdującymi się na stronie WWW, niezależnie od tego, czy zezwalamy na indeksowanie.
- all – indeksuj wszystko.
- none – blokujemy indeksowanie oraz podążanie za odnośnikami na stronie WWW.
I kombinacje:
- index, follow – indeksuj i podążaj za odnośnikami.
- index, nofollow – indeksuj, ale nie podążaj za odnośnikami.
- noindex, follow – nie indeksuj, ale podążaj za odnośnikami.
- noindex, nofollow – nie indeksuj i nie podążaj za odnośnikami.
Dodatkowe argumenty:
- noarchive – nie wyświetlaj w wynikach wyszukiwania kopii zindeksowanej strony.
- nocache – jw., ale odnosi się do wyszukiwarki Microsoftu i Yahoo.
- nosnippet – nie wyświetlaj podglądu i kopii strony WWW w wynikach wyszukiwania.
- noodp – nie wyświetlaj opisu strony pobranej z katalogu dmz (katalog został ostatnio zamknięty).
Nofollow vs odnośniki
Jeśli wykorzystamy argument nofollow, to zablokujemy podążanie za odnośnikami na całej stronie WWW. Ten argument ma charakter globalny. Musimy być pewni, że nie chcemy, aby roboty odwiedzały adresy, do których linkujemy.
Istnieje możliwość lokalnego blokowania odnośników, czyli zastosowania argumentu nofollow w odniesieniu do konkretnego odnośnika. Jeśli chcemy zablokować podążanie za jakimś konkretnym odnośnikiem, to upewniamy się, że dla całej strony mamy zdefiniowany argument follow, a następnie do wybranego odnośnika dodajemy rel=”noffolow”:
<a href="http://nazwa-domeny.pl" rel="nofollow">Robot nie będzie podążał za odnośnikiem</a>
Możemy skorzystać z takiej metody, jeśli nasz odnośnik kieruje użytkownika do strony o niskiej reputacji, na której właściciel stosuje czarne SEO. Dotyczy to także innych podejrzanych i będących w konflikcie z prawem portali. Argument nofollow możemy też wykorzystać jeśli odnośnik prowadzi do zamkniętych części serwisów – przykładowo strony logowania.
Podsumowanie
Plik robots.txt oraz argumenty wraz z wtyczkami pozycjonującymi, to jeden z elementów kontroli procesu indeksowania serwisu. W ten sposób możemy nakreślić ogólne założenia indeksacji (na poziomie pliku robots.txt) oraz wdrożyć szczegółowe praktyki w odniesieniu do konkretnych treści (argumenty i wtyczki). Dodatkowy element zwiększający naszą kontrole w procesie indeksowania to mapa portalu WWW.